
实习生日薪 5500 元,清华姚班凭什么成为 AI 圈的「硬通货」
实习生日薪 5500 元,清华姚班凭什么成为 AI 圈的「硬通货」最近,DeepSeek 接连上了几次热搜。先是因为一张实习 offer 引发围观。一位清华学生在社交媒体晒出录用信息,岗位是 DeepSeek 实习生,税前日薪 5500 元。按每月 22 个工作日计算,月薪超过 12 万元。
来自主题: AI资讯
9046 点击 2026-07-25 21:16
 搜索
搜索
最近,DeepSeek 接连上了几次热搜。先是因为一张实习 offer 引发围观。一位清华学生在社交媒体晒出录用信息,岗位是 DeepSeek 实习生,税前日薪 5500 元。按每月 22 个工作日计算,月薪超过 12 万元。
大家还没等来DeepSeek V4的发布消息,Anthropic家Claude Opus 5今夜即将推出的消息,已经先把全网开发者的热情点燃了。一句"性能强得超乎想象,各大平台正陆续上线"的传闻,将全网的目光再次聚焦在Anthropic上。

一夜之间,Tokenmaxxing成为硅谷热议话题!

@elsewhere 上个月,「elsewhere」报道了 DeepSeek 的融资故事。其中最多人讨论的,莫过于那个传说中的4小时投资人会议。 此去一个月间,梁文锋的各种语录在江湖流传,我们也多方收集到了一些其中内容。

全网等了快三个月!DeepSeek V4正式版,可能最早明日发布,最迟不过这几天。目前,一部分人已提前拿到了DeepSeek V4(GA)灰度测试的权限。一共有两个版本:DeepSeek V4 Flash,DeepSeek V4 Pro。
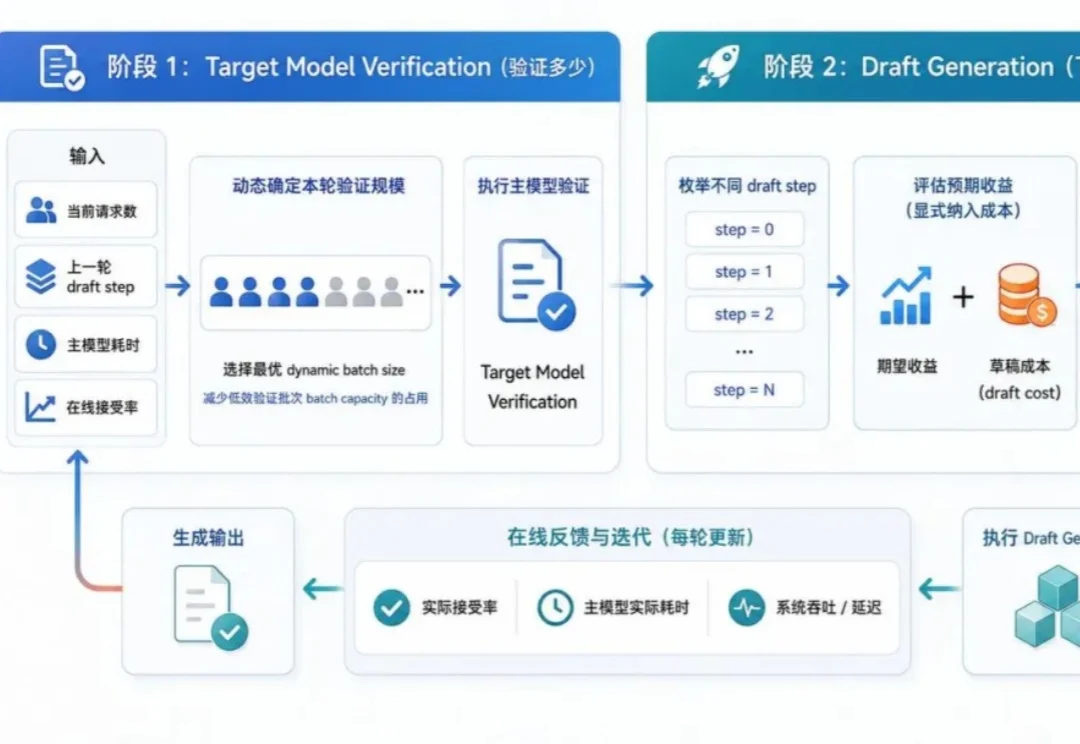
随着 DeepSeek 发布 DSpark,动态 MTP(多 Token 预测)成为了对抗高并发、提升 GPU 利用率的绝对焦点。然而,DSpark 高度绑定特定模型且需要额外训练。

最新消息终于来了——Gemini 3.5 Pro或将于7月17日正式上线。更有意思的是,这个日期恰好与国产大模型DeepSeek V4正式版的发布窗口正面重合。那么这一次,谷歌拿出的究竟是“真金”还是“虚火”?不妨从三个维度拆解一下。

过去 12 个小时,关于 DeepSeek 的消息一个接一个炸出来。

今天,据英国《金融时报》报道,两位知情人士透露,DeepSeek本周开始与新的投资者展开初步接触,讨论开启新一轮融资,投前估值约为710亿美元(约合人民币4813.9亿元),较其首轮融资估值提升约37%。不过,新一轮融资的具体细节尚未最终确定。
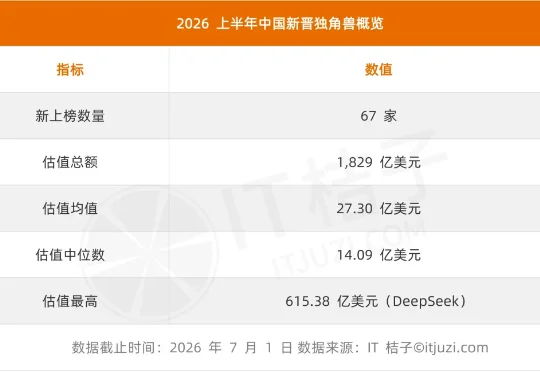
截至 2026 年 7 月 1 日,IT 桔子独角兽数据库信息显示,中国共有 517 家在榜独角兽企业,总估值约 2.39 万亿美元。从估值结构看,呈典型的金字塔分布——57.3% 集中在 10 至 20 亿美元区间,30.8% 在 20 至 50 亿美元,50 亿以上 62 家(12.0%),其中 500 亿美元以上的超级独角兽仅 5 家: